We test the Java Virtual Machine (JVM). Recently some of our JVM product code has been pulled out into shareable runtime components (such as GC, JIT, RAS, Port and Thread libraries) to be used as building blocks for a multitude of other programming languages besides Java, such as Ruby, Python, Javascript (see Eclipse OMR for further details). With this open-sourcing of some of our product code, we need to rethink, rebuild, and refactor our existing test approach. Our new approach can be summarized by this mantra, “Fast, Low and Simple”.
Fast. Tests in open-source communities are typically not run in isolated, pristine test labs. Often they are run on a developers laptop. This means our overnight suite of tens of thousands of tests are not suitable for sharing. We want to design our tests to give us good functional coverage, with the minimal set of tests required. Once the low-level APIs that required testing are identified, we apply combinatorial test design (CTD) principles to new API to keep test numbers low and test cycles short.
Low. We can no longer rely solely on a massive set of Java tests written to exercise Java API, as this would not benefit the other language communities relying on the shared runtime components. We need to push the tests down to the software layers below the languages that are built upon the runtime components. By testing at this language-agnostic layer, we are able to avoid excess duplication and keep the length of the test runs short.
Simple. We’d like our tests to be structured in a standardized way. We should aim to reduce the number of tools required by the tests, and when we need them, look to use open-source tools rather than proprietary solutions. By moving our tests to an open-source test framework, adhering to a coding standard for test source and using common approach for test output, we make tests much easier to maintain, triage and debug.
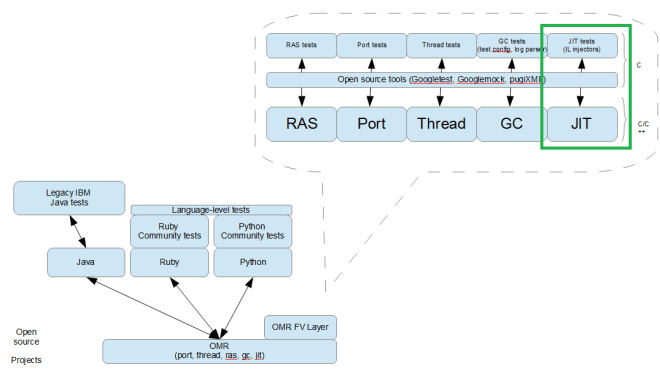
Let’s see our approach looks with an example. We’ll drill down to find some of the simplest units to help test the Just In Time (JIT) component, the opcodes. Why? Because we want low and simple. In computing, an opcode (abbreviated from operation code) is the portion of a machine language instruction that specifies the operation to be performed. Beside the opcode itself, instructions usually specify the data they will process, in form of operands. If the behaviour of the opcode is incorrect, everything built on top of it may be incorrect. So, for the OMR JIT component (Figure 1), we test the opcodes first, to catch any problems as low in the software stack as possible, to the root of a problem.
Figure 1: OMR JIT component
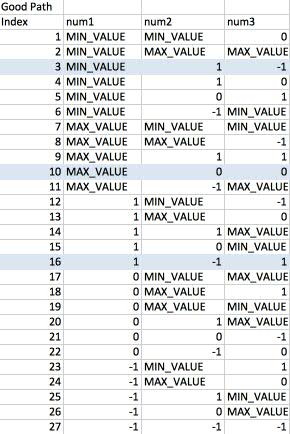
Some opcodes are unary (only one operand), like the return opcode. Some are binary, like add. Some are even ternary. If you break them out by data types, you get an opcodes explosion, iadd (adding 2 integers), ladd (adding 2 longs), etc. There are hundreds of different opcodes.
In an upcoming post, we’ll dig into some details on how we modeled and tested these fundamental pieces.