Combinatorial Test Design (CTD) is a way to design a minimal set of tests that provide good/adequate functional coverage. This is a brief overview of CTD to introduce the concept and describe how we are finding it useful for Functional Verification (FV). It is an approach that can be applied at every level of testing, including system testing, but for the purpose of this guide, we will use FV examples. When we test our products, we want good functional coverage of our source code. Functional coverage does not mean the same thing as code coverage. 100% code coverage means that our tests exercised every line of the source code. That sounds good, but it doesn’t mean much, if our tests are poor. 100% functional coverage means we exercise all lines of the source code with all possible variants or input values of the code. To be clear, it is unrealistic to achieve 100% functional coverage and if we did, it would be too many tests to actually run and maintain. CTD offers a better approach, one that brings us high functional coverage in as few tests as possible.
Let’s take a look at a simple example:
static Integer mathyJunkFunction(int num1, Integer num2, String num3) {
return new Integer(num1) / (num2 + new Integer(num3));
}
If we test this function with the following:
Integer result = mathyJunkFunction(1, new Integer(1), “1”);
We will have 100% code coverage, but we will have not done a very good job of testing the function. As you can see in this naive example, we see multiple defects that this test does not catch.
Defect 1: What if num3 has a value of null (throws NumberFormatException)?
Defect 2: What if num3 is “1” and num2 is -1, or “0” and 0, or any other combination that sum to 0 (throws ArithmeticException)?
Defect 3: What if num2 is null (throws NullPointerException)?
This is a very simple example, that does not take into account implicit inputs or environmental factors that may affect the behaviour of real world source code, such as environment variables, command line options, platform specific behaviour or hardware configuration details. In real world cases, we would also include any implicit inputs and their values. Let’s ignore implicit inputs for our example. The 3 parameters of the function are the explicit inputs we need to consider in our tests. If we want to model the test space for this function, we need to look at the “values of interest” for each of them. If our parameters were custom data structures or objects, we would need to provide the list of ‘equivalence classes’ as the values of interest. In this example, we are dealing with known data types, so our job of defining ‘values of interest’ to use in our tests is easier.
num1 (integer): {MAX_VALUE, 1, 0, -1, MIN_VALUE}
num2 (Integer): {MAX_VALUE, 1, 0, -1, MIN_VALUE, null}
num3 (String): {“MAX_VALUE”, “1”, “0”, “-1”, “MIN_VALUE”, null}
If we tested all combinations of all values of the 3 inputs (100% functional coverage), we would have 5 x 6 x 6 = 180 test cases. But as many studies of typical source code have shown, most defects are caused by faulty logic involving 1 input or the interaction of 2 inputs. Because of this, we know that if we apply limits, creating a test case for every pair of values (known as pairwise testing), we will typically have 80+% functional coverage (unless the code under test is atypical of most source code). When we take every unique combination of value pairs, we arrive at 29 test cases (27 good path, 2 bad path) as shown in Table 1 and 2.
Table 1: Pairwise testing for mathyJunkFunction() – Good Path
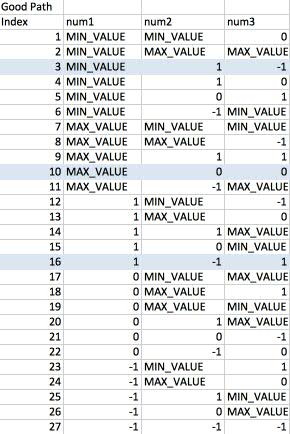
Table 2: Pairwise testing for mathyJunkFunction() – Bad Path

29 test cases are more manageable than 180. When we look at the list of test cases, we see that for the 3 defects we flagged in our naive example,
Test Case 1 of the Bad Path list (in Table 2) would catch Defect 1 (the NumberFormatException)
Test Case 2 of the Bad Path list would catch Defect 3 (the NullPointerException)
Test Cases 3, 10, 16 catch Defect 2 (the ArithmeticException)
With inspection of the source code, we could decide to reduce our test case numbers even further, but if we were testing something more complex, or were black box testing, we could implement the set as described and have confidence that we would catch the majority of defects. We have applied CTD to a lot of the FV in the OMR Eclipse project and designs relating to other 2015 feature requests. Our plan is to enhance our understanding and use of CTD in 2016 including some automation experiments and to continue to see the many benefits from our efforts.
